Mark Graham has posted a critique of a “Twitter map” that featured in the Economist at Zerogeography. The map was compiled by Portland Communications and Tweetminster and shows the number of tweets per country (original version of the map can be found in this presentation by Portland Communications):
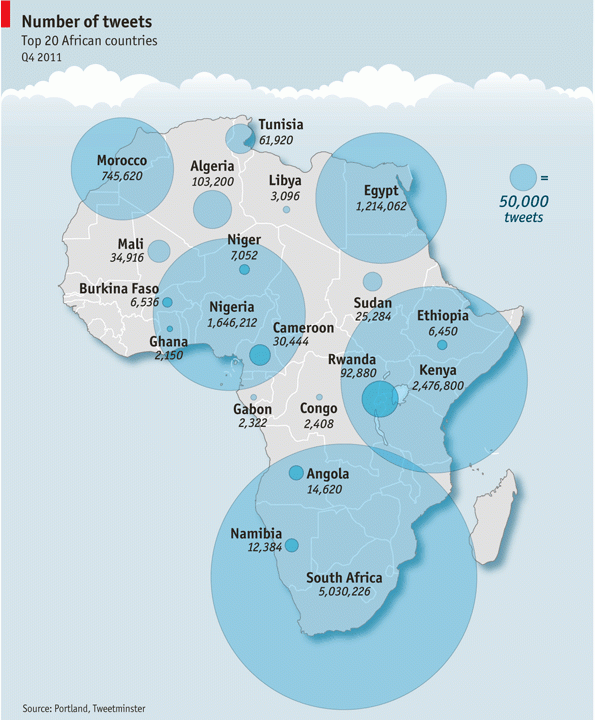
Mark Graham raises these interesting points regarding this map:
- 11m Tweets in Africa over a three months period is probably vastly underestimated, since the joint Portland Communications/Tweetminster analysis looked only at geocoded tweets.
- The analysis doesn’t account for the provencance of the tweets: are many of them issued by few users or are actually many people behind the many tweets of a country? This is likely a very relevant point, since it is found with many crowdsourcing projects that a small minority of the users contributes the majority of the content. It may be the same with Twitter, the only question which remains then is: could it be that the proportion of heavy contributors varies between countries (thus harming comparability of countries)
- The analysis doesn’t relate the number of tweets to the number of inhabitants. We have thus no way of knowing whether a big number of tweets means an extraordinarily high proportion of Twitter users in the population, or not.
Mark states that in a study conducted by him and his team using the Twitter Streaming API, it was found that only 0.7% of all tweets indeed contain geolocation information. (and thus the Africa Twitter map is based on a really small sample of the tweets which have been sent from within African countries!). That proportion was something I have wondered about since I have started to tinker with the Twitter REST API a few weeks ago. Other than the Streaming API (the so-called “firehose”), the REST API has tight query limits, so I haven’t acquired a big enough sample of tweets to actually make the judgment regarding the prevalence of location information in tweets (acquiring a random sample of tweets is also not the aim of my studies).
As Mark further points out this shortcoming on the data side makes the map potentially useless, in the worst case even misleading: Users in different countries may expose location in their tweets with different probabilities, due to for example:
- different brand mix of end user devices (for example, different prevalence of smartphones versus dumbphones (which can use Twitter via SMS)
- different mix of Twitter clients. Twitter clients may expose the location sharing settings in different ways and may rather encourage or discourage a user to opt into or out of location sharing
- varying awareness of, or views on, privacy issues around location sharing
- different societal norms towards location sharing
If the prevalence of location sharing is different in different countries, the Africa Twitter map cannot serve even as a proxy of the true numbers of Tweets sent from African countries.
Further takeaways thanks to Mark Graham:
- Using the location information in description fields of Twitter users’ profiles is a bad substitute for actual location information attached to tweets.
- Time zone information as another approach to rough positioning of a Twitter user isn’t a feasible alternative route either, since many users don’t bother to set it in their profile.
- And, most importantly and generally applicable: Any analysis of data from social media or crowdsourcing initiatives has to scrutinise the data for potential confounding variables, inherent biases, flaws in data collection (sampling), data processing and analysis. No analysis is complete without these questions asked – if they’re not clarified in the analysis, it’s the end user’s duty, though unfortunately it can be difficult without access to the raw data.
We’ve been collecting Tweets from the garden-hose sample and a keyword-based search of the streaming API for many months, and I can support the critique. In our case, we have roughly 1% of Tweets geocoded. We also looked into the various ways of using location (searching for placenames in the text, the user location, and any place info added by Twitter). We also found that user profile location is highly unreliable as a substitute. Furthermore, the whole geocoded issue is a terrible mess, because of the various ways a Tweet can be geocoded: Via GPS of the device, or via a user choice of a place and subsequent geocoding by Twitter. In both cases, the results can vary, because of user preferences and software design. For example, a Twitter app can present the user a selection of places to choose from, which does not have to be exhaustive. A user can set a level of detail for Twitter geocoding, e.g. neighborhood, city, country. Some apps put the device’s GPS coordinates in the user profile location info. Etc. Etc.
Thanks for your more detailed insights, Frank. So, from your words I take you actually declare Twitter’s location information pretty much devoid of any analysis value, as of now? Or would that be an exaggeration and there may be some use cases where Twitter location information is okay to rely on?
I wouldn’t go that far. Simply because of the amount of info available and the richness of the metadata (about user accounts, interactions, etc.), Twitter location information has potentially high analysis value. But you need to be aware of the serious limitations, i.e. the sample of geocoded Tweets (and their authors) is likely not representative of the whole Twitterverse, using user profile location is not a good substitute for actual Tweet location, device GPS accuracy may be low, and you don’t always have the lineage (origin) of the geocoding (i.e. user choice, device, Twitter). The other option to increase geocoded Tweets is to geocode them yourself, by extracting toponyms from the content and look them up in a gazetteer. That’s what we’re doing. We have not yet examined the relation between our (simplistic) approach and the “official” Twitter or user device GPS geocoding. It’s on the agenda…