Some weeks ago I visualised the Swiss cantons (states) and their population numbers using what information visualization scientists call a linked view. You can click through to the actual, interactive visualization: here in German or here in French. In what follows I’ll describe the steps of data preparation for this visualization. I decided to keep the specifics on the implementation in D3.js for a third post in order to spare your scroll-wheel and -finger (so stay tuned for that one).
Intro
Welcome to the second part of this series in which I describe the production of this linked view with a population cartogram (top right):
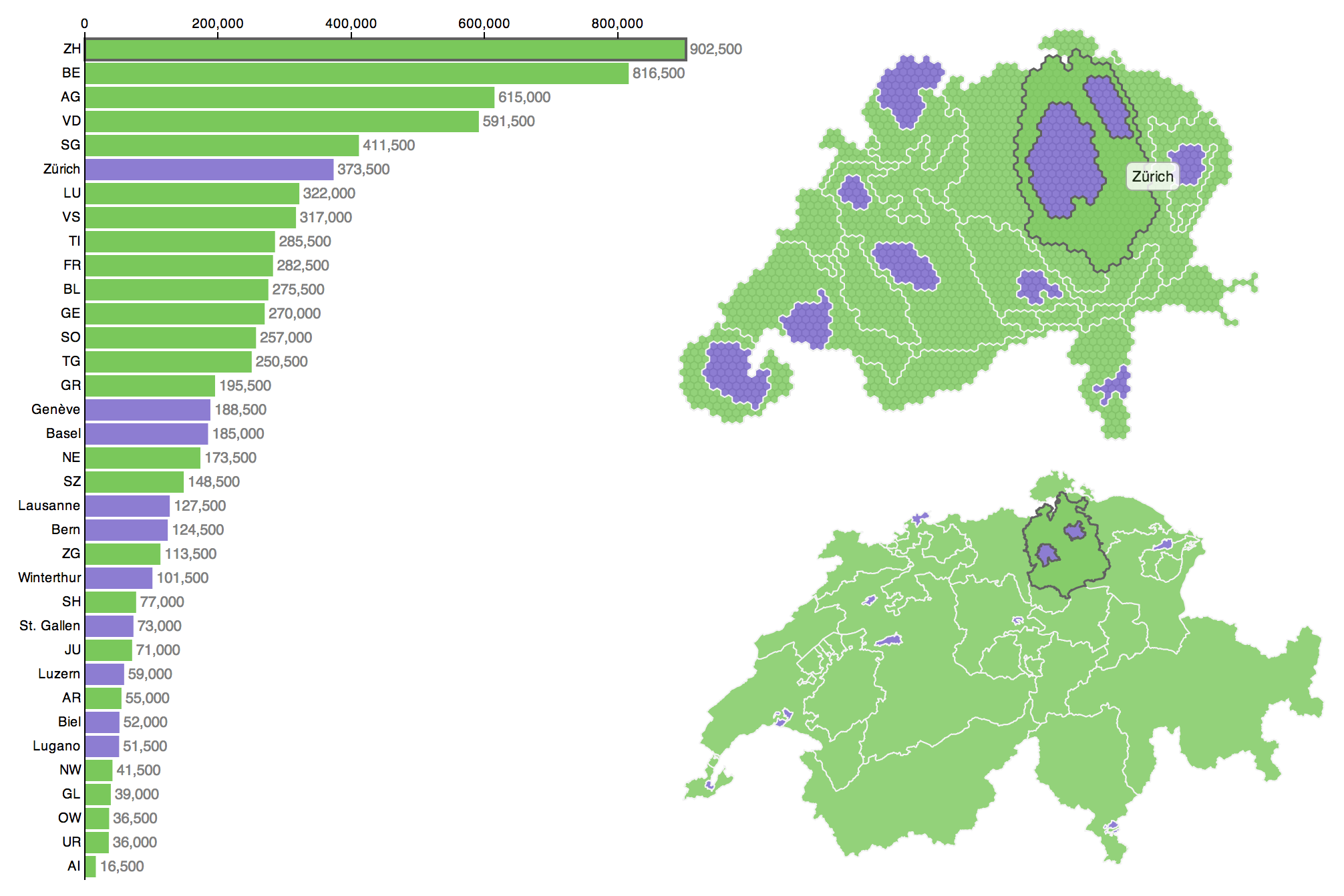
In case you missed it: in the first post of this series, you can read about the conceptual thinking that went into this visualization. But now let’s dive into some geodata-crunching:
Technically
GIS pre-processing
In what follows, I’ll try to give you a thorough description of my approach at data processing. I’ll include some screenshots of intermediate results. Obviously, I don’t know how familiar you are with GIS and spatial analysis terminology, so please bear with me if my description is too exhaustive. Conversely, speak up in the comments section, if I have forgotten something or something is not clear. I did all of the GIS analysis in Esri ArcGIS, however, any GIS that can handle vector data will do.
I started off with the following input data:
- Outlines of administrative units (cantons and cities)
- Spatially distributed population data from Swiss census
The preparation of the administrative units was quite straightforward: I applied a Union operation in GIS (ArcGIS Help Topic here). Then I did some tidying of the attributes and applied a set of geometric simplifications (polygon outline generalisations). The purpose of these is basically weeding out vertices from the geometries while preserving shape as well as possible. The bigger goal being, of course, simplifying the geometries enough for a fluid web experience down the line.
Swiss census data comes as a point grid at 100 meters resolution. Precise data characteristics don’t matter too much. And one could also use a thematic variable that comes at the same resolution as the display units – cantons and cities in this case. While the handling of canton/city level thematic data would be much easier, the spatially distributed thematic variable in this case allows for a more representative cartogram. If you wonder why, consider, for example, a US setting: Salt Lake City would cause a big local distortion in a cartogram using spatially distributed data, whereas its population would be spread out uniformly throughout all of Utah, if you use state-level data. This effect causes visible differences in the cartogram in regions where population distribution is not spatially uniform.
The GIS processing chain starts with these steps:
- Generation of a grid (in my case at 5 km resolution, but that number is a bit dependent on the resolution of your input data, your area of interest and maybe your application; as a rule of thumb, I’d suggest a grid resolution that is similar to the size of your hexagons). Any regular tesselation other than a rectangular grid will also do.
- Union operation on the grid cells and the administrative units. This yields smaller spatial analysis units, that follow the boundaries between administrative units.
- Spatial join of thematic variable to the new spatial units. A spatial join is a GIS operation where the spatial relationship of entities in two different datasets is evaluated. If a specified relationship is fulfilled, the characteristics of the features in the join dataset are joined to the features in the target dataset. The spatial relationship for this operation was containment (i.e. the criterion was: is a given census data point within the spatial unit at hand?). The join operation encompassed summing up the values. The overall process yields the sum of the population at all census data points which fall within a given spatial analysis unit – or, without the GIS lingo: the total population per unit).
For distortions you need a Scape… toad
The resulting data in Shapefile format was then transferred to the cartogram software Scapetoad. Scapetoad is a freely available Java software developed in the Choros Laboratory at EPFL in Lausanne. It employs the diffusion-based cartogram algorithm by Gastner–Newman. I did several model runs and iteratively tuned the algorithm parameters. That encompassed mainly striking an acceptable balance between subjective quality of the result and cartogram computation time. Unfortunately, I cannot give heuristics for this, you’ll really simply have to try with your data.
When I was happy with the result, I re-imported the cartogram dataset from Scapetoad into the GIS and used a Dissolve operation to aggregate the units back into regions (again, any GIS will do, but the precise name for the operation may vary).
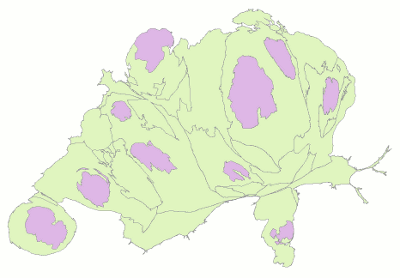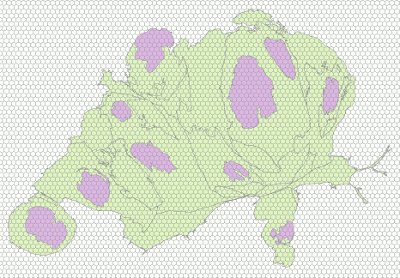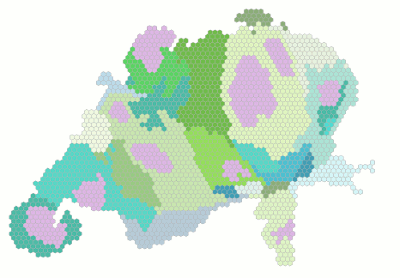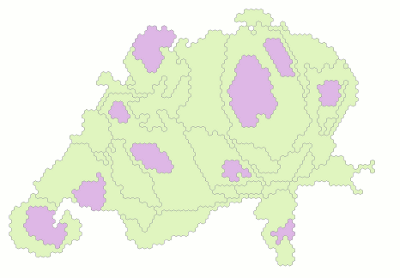
Enter the hexagons
After these steps, I used a third-party add-on to ArcGIS to create a hexagonal grid (other GISs may have built-in support for creating hexagons). I chose the resolution of this grid to be similar to the one used for creating the spatial units before the spatial join and cartogram generation. I think that is an okay heuristic for dealing with resolution sensitivity or scale issues and MAUP (each of these can spark long discussions, but I’ll spare you).
Then I used another spatial join: this time on the distorted geometries and the hexagonal grid. Thus, I could automatically assign hexagons the respective region code, whenever the hexagons where located completely inside a distorted region. I did not use automatic conflict resolution on hexagons located on borders between distorted regions. While doing this would be perfectly possible in GIS, I actually wanted the wiggle room these unassigned hexagons gave me.
To conclude the cartogram generation, I manually assigned the border hexagons to adequate administrative units. In this subjective approach I employed two important cartographic principles:
- shape preservation
- topology preservation
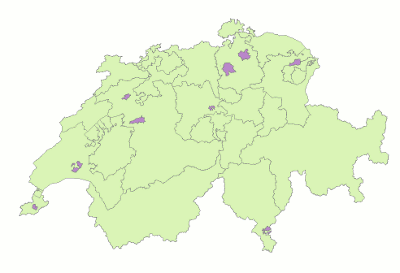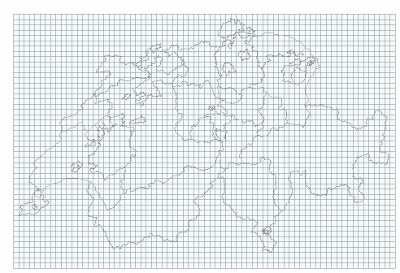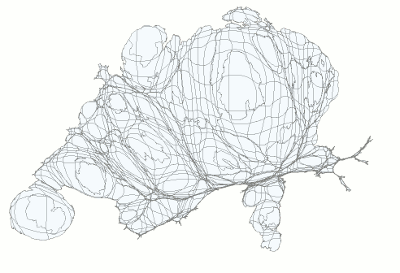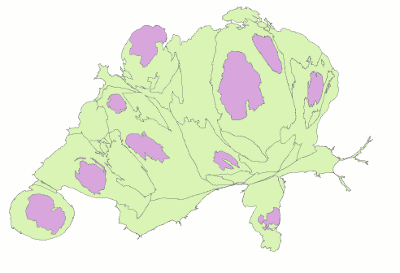
It may seem odd to talk of shape preservation in the case of a cartogram (whose point are the distortions), but I hypothesise that, also for cartograms, preserving some key features helps people appreciate the geometries better. As an example, I maintained the small “antennae” of Grisons (near the right/eastern edge of below graphic) although I thus locally overestimated the population a bit (see graphic below). I also overemphasised the bays of the lakes bordering some cities (Geneva (bottom-left), Lucerne (below center) and Zurich (biggest city)). Features such as these are so well-known by people familiar with the geography, that they help those users recognise the unusual geometries.
Examples for preservation of topology were cantons of Obwalden, Nidwalden and Uri (near the center). In an early iteration, these touched the border of Italy in the south, between Valais and Ticino. This is not the case in geographic space, though. I manually overrode that configuration in order to replicate the topology of the geographic regions closely, thus also fostering recognition.
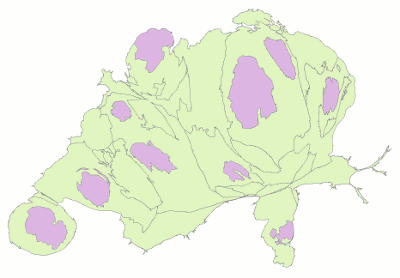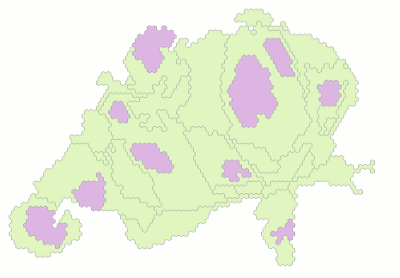
Quality checking and file format conversion
Throughout these manual interventions, I kept an eye on the quality of the representation using a simple, dynamically updated scatterplot that related the number of hexagons per distorted region with the total population of the respective region. The coefficient of correlation, R2, started out high and with the end result I achieved a value greater than 0.99, that is the representation in the cartogram was very close to the actual population numbers: Nice!
For the visualization I couldn’t use the antiquated Shapefiles, but instead opted for the Topojson format by Mike Bostock (who also happens to be the creator of D3). Topojson of course plays well with Javascript and thus also D3. In my visualization, I wanted to display three datasets: the aggregated distorted geometries of cantons and cities, the tiny hexagons which they consist of as well as the undistorted geometries for my reference map. Thus, I converted all these datasets to Topojson files using an online service called shpescape. But other options do exist, such as GDAL/OGR (see Mike’s approach with that tool in his tutorial).
With the first visualization prototype, a problem became apparent: For the cartogram, the numerous small hexagons were supposed to be loaded and displayed first. Only after, the cantons and cities should be overlaid on them, with a slight transparency. But ever so often the considerably bigger hexagon Topojson file would be loaded and displayed in D3 only after the cantons and cities and thus the hexagons were on top of the latter instead of the other way around. An easy way to avoid this was the merging of all data files into one big file. To that end, I used the following syntax adapted from the afore-mentioned tutorial by Mike (topojson needs to be installed at this point):
topojson -o swiss_regions.json hexagons.json distorted_units.json undistorted_units.json
And with the first line of code: That’s it with data-processing. I started out from a “normal” official cantons and cities dataset and Swiss census data. Through various GIS processing steps, the use of Scapetoad for distorting, some more GIS including manual interventions and conversion, I obtained the Topojson file that would be at the core of my visualization.
The manual steps in the above process may seem tedious, but they took maybe an hour at most in my case. It’s really a question of your setting: complexity of the shapes you’re dealing with and the size of your hexagons, mostly (one of these you can choose ;).
I’m having some hard time to understand how to join the data to the map using QGIS. Will be great to have just a basic example with a simple dataset and a map, and all the steps to get to the JSON file.
I’m familiar with d3, and I find Mike Bostock’s tutorial about building a map – http://bost.ocks.org/mike/map/ , very straight forward but still tying hard to figure out how to generate the geo JSON for the hexagons map.
You seem to be missing a part of canton Basel-stadt.
But other that that, congratulation on the amazing results.
I want to try to follow your workflow to represent the results of the latest Swiss election. This would be way better than the many gemeinde maps that do not represent the population.
Thank you very much! You probably mean Riehen and Bettingen? I think they are just considerably too small to show up in this map.