For a private project of mine as well as in the context of a data analysis foray on behalf of GeoBeer, I wanted to use the content that has been published on the GIS-centric message board Geowebforum. In order to achieve this, I had to do some webscraping. To that end, I used Python and BeautifulSoup.
Two principal news sources
The GIS community of Switzerland has two forums for discussions and the exchange of ideas, I’d say: First, there is the #SwissGIS list on Twitter: This is a Twitter list of “Switzerland-based people who talk about spatial data science, GIS, geoviz, carto and geo” that is curated by me.
At the time of writing, the list features about 400 members and about 100 subscribers. I use the list as a means to follow Switzerland-related GIS news. To that end, I display the list as a column in Tweetdeck. Over time, the SwissGIS list has been the subject of several analyses. To me, this Twitter list is an invaluable resource for learning, sharing, and community building. It is also the nucleus of the GeoBeer event series that Stephan and I started in 2013 – after one of those analyses that are linked to above. But this is a topic for another post.
The second forum for GIS in Switzerland, in my perception, is the Geowebforum. It is a message board-style online forum in which, after free registration, anybody can share their news, announcements and ideas around GIS. The content is greenlit by a small group of moderators. This makes the forum a more static marketplace of ideas. As opposed to Twitter, it’s rare to see a thread growing into a discussion of 2, 3 or even more posts.
(Of course, there are some other relevant channels besides Twitter and Geowebforum. In my case, e.g.: personal interactions, community events such as GeoBeer, and LinkedIn.)
Getting the data
For private projects of mine, I wanted to use the content that has been published on Geowebforum since its initiation in 2003. While the content is public (anybody can read the entirety of the forum contents, even without registration), it is not available in structured form (other than the RSS feed as was pointed out to me; but the feed only contains a small subset of all posts, namely the most recent ones). Thus, in order to get the content of Geowebforum into a usable form, I did some webscraping and data structuring in a database.

To that end, I used Python, the urllib2 library for making HTTP requests and the BeautifulSoup library for analysing and extracting the page content. You can find all code associated with my project (with an open licence) (as well as the resulting database of Geowebforum content) on my GitHub: github.com/rastrau/geowebforum-scraper. The work is done in scrape-geowebforum.py. This script sets up an SQLite database and scrapes the forum content into it.
The script first iterates through ‘topics’ – what I called the highest level in the information architecture of the Geowebforum. In the screenshot above you can see, for example, the first page of the topic ‘Jobs’, listing its threads.
The Python code to request that page and to find all links to threads looks as follows:
page = urllib2.urlopen('%s&offset=%s' % (topic_url, offset))
soup = BeautifulSoup(page, 'lxml')
thread_links = soup.find_all('a', {'class': ['threadtitle']})
With the call to soup.find_all(‘a’, {‘class’: [‘threadtitle’]}) we can extract all hyperlink DOM elements (<a href=”….”> tags) of class “threadtitle” in the page. Later, when iterating through the collected thread links, we can access the name of the thread as well as the hyperlink to the thread as follows:
thread_name = thread_link.string thread_url = 'https://geowebforum.ch/%s' % thread_link['href']
Similarly, the code iterates through all topics, all threads within each topic and all posts within each thread. It records the URLs and the titles of these items as well as the information architecture of the website. For posts, it extracts a lot of additional information such as the post title, the post content with and without HTML tags, the post time and the anonymised post author.
There are some peculiarities I had to take care of: e.g., upon paging too far through a thread, Geowebforum does not display an error page or return an HTTP error code, but rather shows an emptyish page – the structure of which I detect using BeautifulSoup in order to stop the paging process.
Structuring the data
The data that is obtained from scraping is structured and filled into an SQLite database that was set up at the start of the processing. This is done using the sqlite3 library of Python. For example, given an active connection to the database and a cursor, the code for ingesting thread data into the database looks as follows:
def ingest_thread(cursor, thread_id, thread_name, thread_url, topic_id):
cursor.execute("INSERT INTO threads VALUES (?, ?, ?, ?, ?)",
[thread_id, thread_name, thread_url, topic_id, 0])
return
The database is further set up with triggers, using Python. This way, upon adding a post into the table of posts, a trigger fires and updates the post count per thread in the table pertaining to forum threads.
As a further add-on, I included a classifier of the language of posts. This is done using the langdetect Python library. This library lets me compute the probability that a post is written in German, French, Italian or English. Out of the four Swiss national languages the (by far) smallest, Romansh, is not covered by langdetect. But I have my doubts that there are any posts in Romansh in the Geowebforum. Besides the language-specific probabilities, I store the most likely language in the database as well. But keep in mind that probabilities can be a very sensible metric to look at too, as, in my impression, a non-insignificant amount of forum posts combine two or more languages.
Getting the data
You can get all the data that I extracted from the Geoebforum between 2003 and 2018 from github.com/rastrau/geowebforum-scraper. Specifically, you’ll want to download the SQLite database data.sqlite. You can look at, and analyse, this dataset with any SQLite compatible tool, for example DBeaver or R using RSQLite.
The database contains four tables:
- metadata
- topics
- threads
- posts
All these tables are described in detail in the Readme of my repository. The posts table contains most information. It stores the following attributes for each forum post:
post_id(int, primary key): numeric ID of the geowebforum post (not linked to geowebforum.ch, but inherent to geowebforum-scraper)post_time(text; SQLite has no datetime format): Timestamp of when the post was made. The timestamp follows the format%Y-%m-%d %H:%M:00.000.post_author(text): Hashed (encrypted) name of the author of the post.post_content(text): Content of the post complete with HTML tags, i.e.post_contentfor example contains link targets.post_text(text): Same aspost_contentbut with HTML code removed.post_textcorresponds to the text you see when you read a post in your browser.post_lang(text): Most likely language of the post as detected using the Python packagelangdetect. Possible values arede,fr,itandenfor German, French, Italian and English, respectively. Romansh / Rumantsch cannot be detected bylangdetect.de(real): probability in the interval of 0 to 1 of the post being in German.fr(real): probability in the interval of 0 to 1 of the post being in French.it(real): probability in the interval of 0 to 1 of the post being in Italian.en(real): probability in the interval of 0 to 1 of the post being in English.thread_id(int, foreign key): numeric ID of the geowebforum thread that contains this post.topic_id(int, foreign key): numeric ID of the geowebforum topic that contains this post.
Insights
I posted some insights that can be gained from this dataset complete with the code (R and SQL) that was used to generate them. Here are some examples (you can explore the full list here):
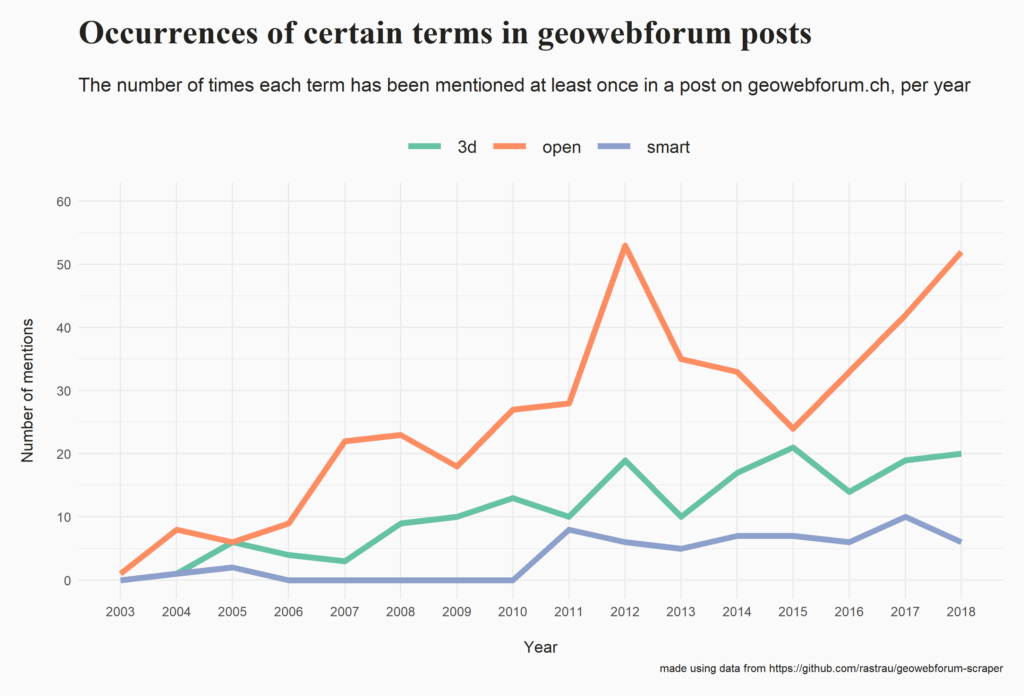
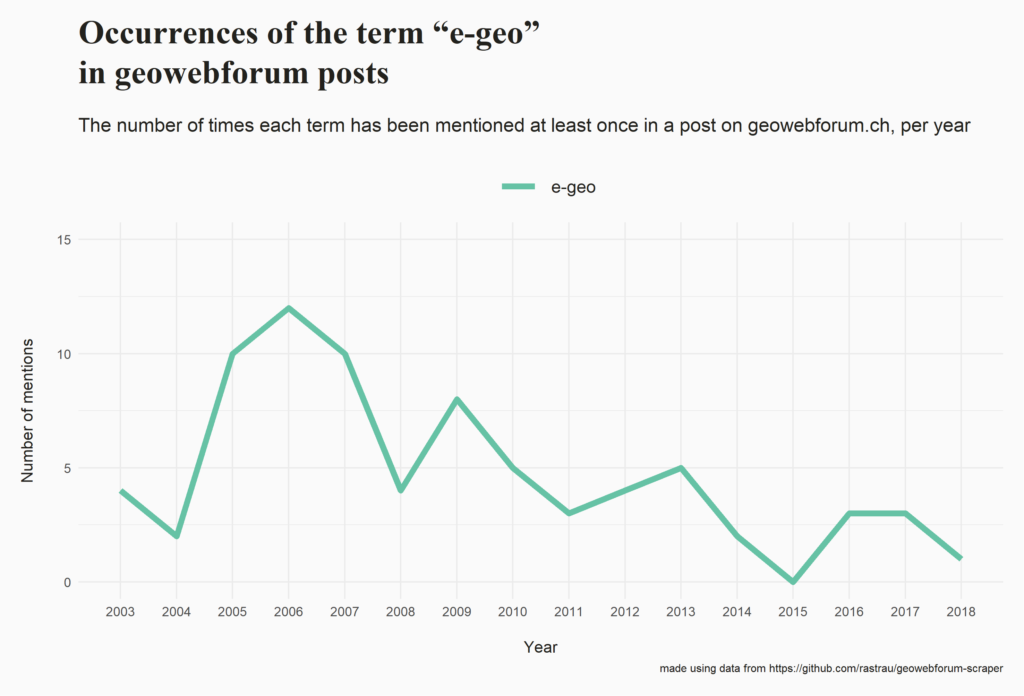
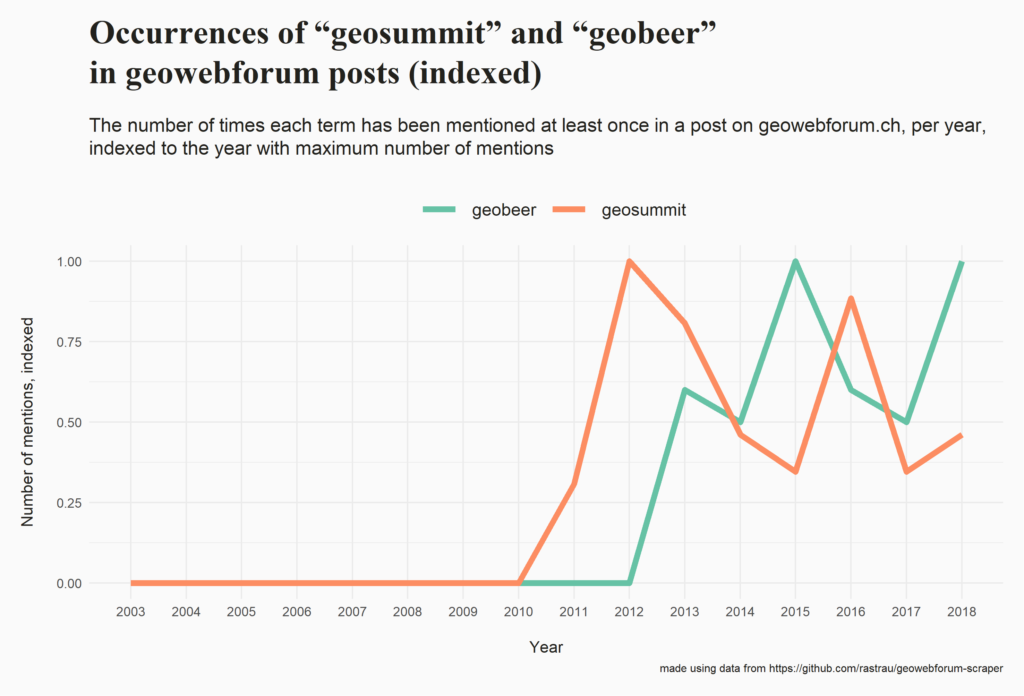
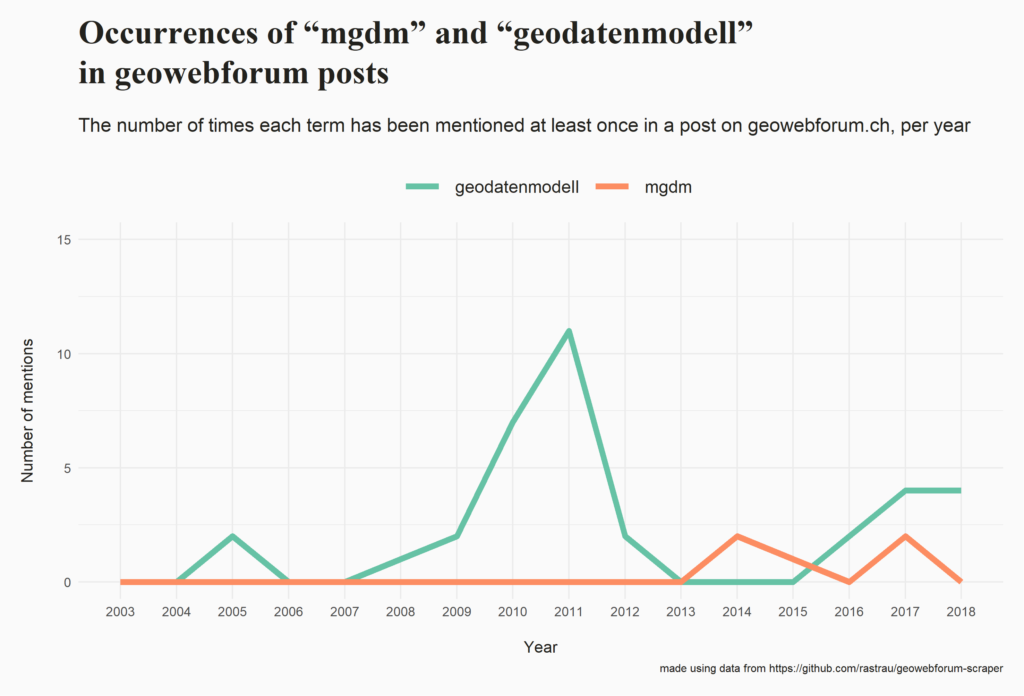
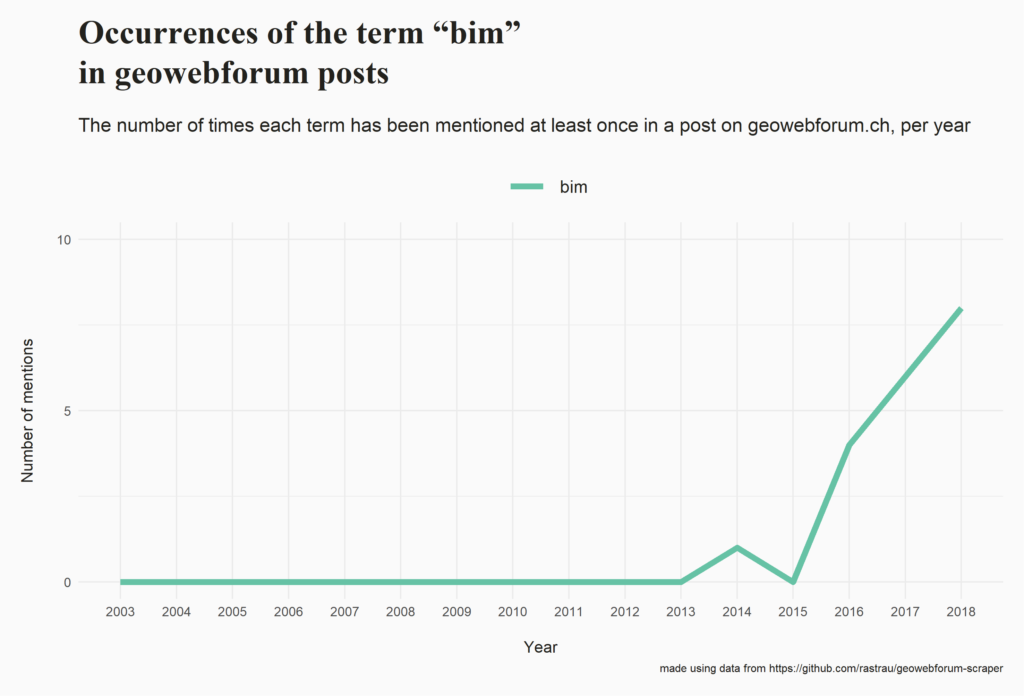
Please let me know if you build something on top of this data, if the code helped you or if you come across an interesting insight!